%load_ext autoreload
%autoreload 2
import il_tutorial.cost_graphs as cg
import il_tutorial.util as util
from IPython.display import HTML
HTML('''<script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.input').hide();
} else {
$('div.input').show();
}
code_show = !code_show
}
$( document ).ready(code_toggle);
</script>
The raw code for this IPython notebook is by default hidden for easier reading.
To toggle on/off the raw code, click <a href="javascript:code_toggle()">here</a>.''')
Natural Language Processing
(COM4513/6513)
Imitation Learning for Structured Prediction
Andreas Vlachos
a.vlachos@sheffield.ac.uk
Department of Computer Science
University of Sheffield
Based on the EACL2017 tutorial
with Gerasimos Lampouras and
Sebastian Riedel
Some structured prediction tasks we know
- part of speech (PoS) tagging
- named entity recognition (NER)
Input: a sentence $\mathbf{x}=[x_1...x_N]$
Output: a sequence of labels $\mathbf{y}=[y_{1}\ldots y_{N}] \in {\cal Y}^N$
More Structured Prediction

Syntactic parsing, but also semantic parsing, semantic role labeling, question answering over knowledge bases, etc.
Input: a sentence $\mathbf{x}=[x_1...x_N]$
Output: a meaning representation graph $\mathbf{G}=(V,E) \in {\cal G_{\mathbf{x}}}$
More Structured Prediction

Natural language generation (NLG), but also summarization, decoding in machine translation, etc.
Input: a meaning representation
Output: $\mathbf{w}=[w_1...w_N], w\in {\cal V}\cup END, w_N=END$

But we train a classifier to predict
actions constructing the output.
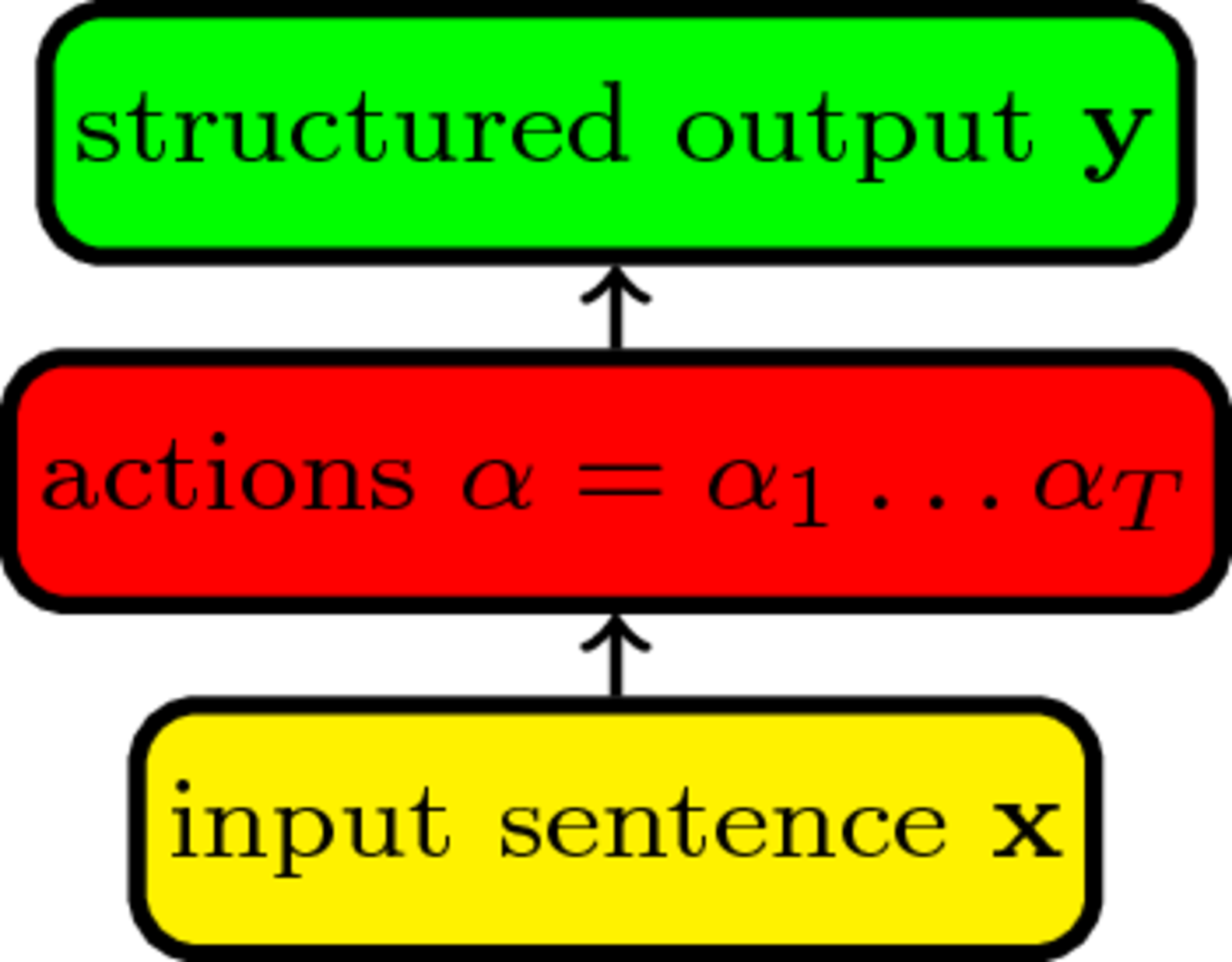
Originated in robotics¶
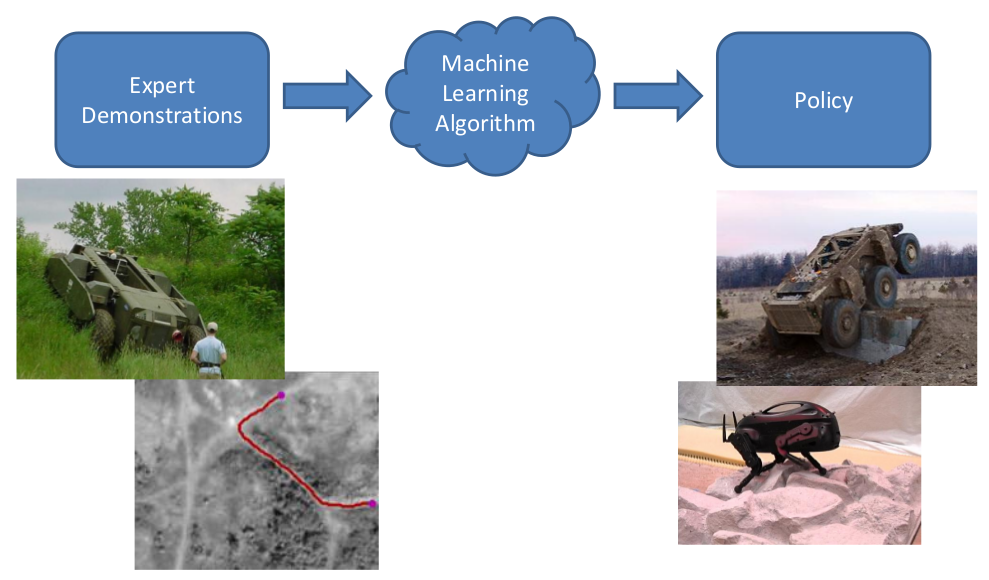
Meta-learning: better model (≈policy) by generating better training data from expert demonstrations.
Incremental modeling, a.k.a:
- local
- greedy
- pipeline
- transition-based
- history-based
Joint modeling¶
A model (e.g. conditional random fields) that scores complete outputs (e.g. label sequences):
$$\mathbf{\hat y} =\hat y_{1}\ldots \hat y_{N} = \mathop{\arg \max}_{Y \in {\cal Y}^N} f(y_{1}\ldots y_{N}, \mathbf{x})$$- exhaustive exploration of the search space
- large/complex search spaces are challenging
- efficient dynamic programming restricts modelling flexibility (i.e. Markov assumptions)
Incremental modeling¶
A classifier predicting a label at a time given the previous ones:
\begin{align} \hat y_1 &=\mathop{\arg \max}_{y \in {\cal Y}} f(y, \mathbf{x}),\\ \mathbf{\hat y} = \quad \hat y_2 &=\mathop{\arg \max}_{y \in {\cal Y}} f(y, \mathbf{x}, \hat y_1), \cdots\\ \hat y_N &=\mathop{\arg \max}_{y \in {\cal Y}} f(y, \mathbf{x}, \hat y_{1} \ldots \hat y_{N-1}) \end{align}- use our favourite classifier
- no restrictions on features
- prone to error propagation (i.i.d. assumption broken)
- local model not trained wrt the task-level loss
Imitation learning¶
Improve incremental modeling to:
- address error-propagation
- train wrt the task-level loss function
Meta-learning: use our favourite classifier and features, but generate better (non-i.i.d.) training data
To apply IL we need:
- transition system (what our classifier can do)
- task loss (what we optimize for)
- expert policy (the teacher to help us)
Transition system
The actions $\cal A$ the classifier $f$ can predict and their effect on the state which tracks the prediction: $S_{t+1}=S_1(\alpha_1\ldots\alpha_t)$
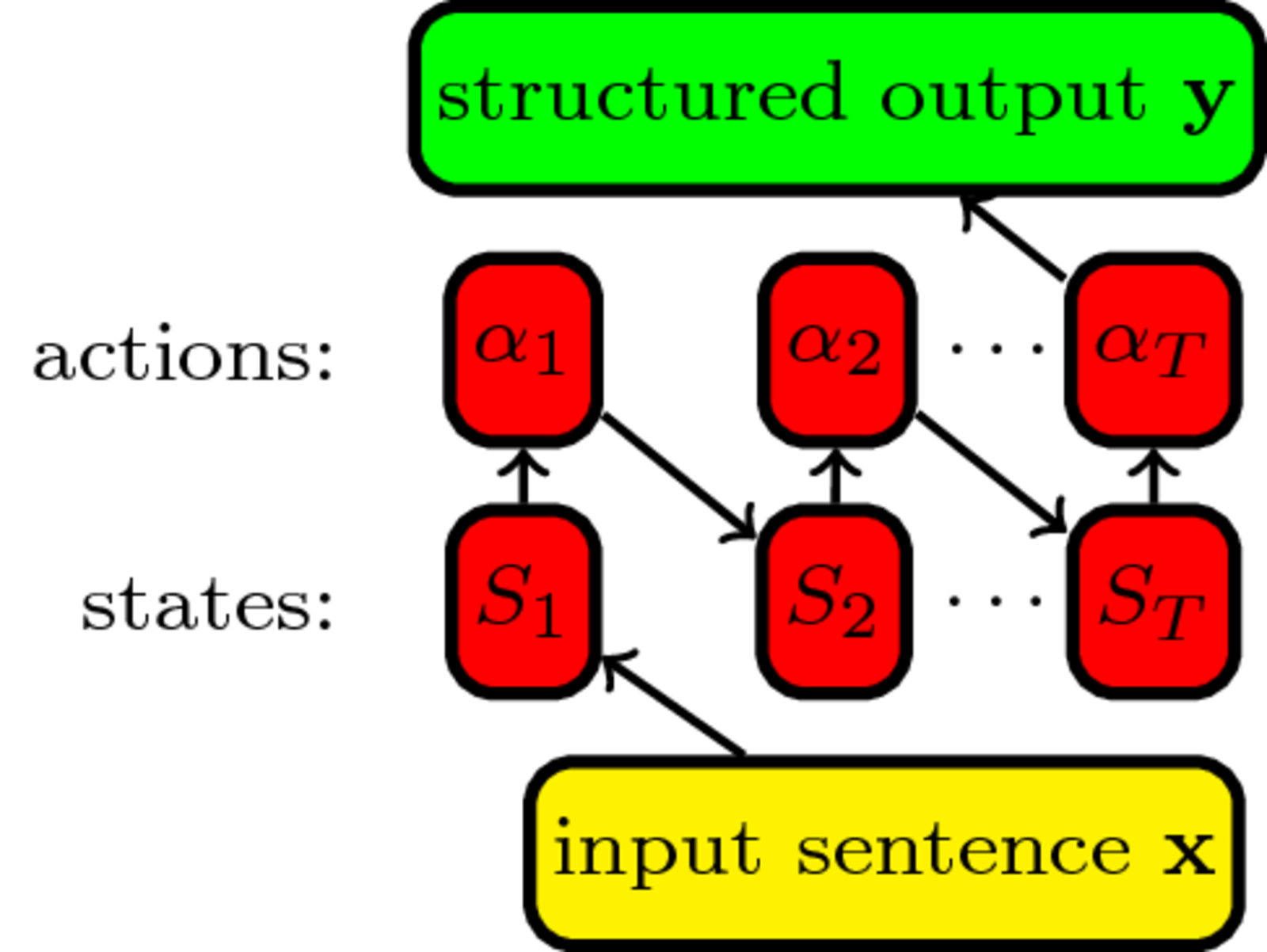
Transition system
\begin{align} & \textbf{Input:} \; sentence \; \mathbf{x}\\ & state \; S_1=initialize(\mathbf{x}); timestep \; t = 1\\ & \mathbf{while}\; S_t \; \text{not final}\; \mathbf{do}\\ & \quad action \; \alpha_t = \mathop{\arg \max}_{\alpha \in {\cal A}} f(\alpha, \mathbf{x})\\ & \quad S_{t+1}=S_t(\alpha_t); t=t+1\\ \end{align}
- PoS tagging? for each word, left-to-right, predict a PoS tag which is added to the output
- Named entity recognition? As above, just use NER tags!
Supervising the classifier¶
What are good actions in incremental structured prediction?
Those that reach $S_{final} = S_1(\alpha_1\ldots\alpha_T)$ with low task loss:
$$loss = L(S_{final}, \mathbf{y}) \geq 0$$- PoS tagging? Hamming loss: number of incorrect tags
- NER? number of false positives and false negatives
Action assessment¶
How many incorrect PoS tags due to $\alpha_6$ being NNP? 0
How many $FP+FN$ due to $\alpha_6$ being B-PER?
Depends! If $\alpha_7$ is
- I-PER: $0$ (correct)
- O: $2$ (1FP+1FN)
- B-*: $3$ (2FP+1FN)
$FP+FN$ loss is non-decomposable wrt the transition system
Expert policy¶
Returns the best action at the current state by looking at the gold standard assuming future actions are also optimal:
$$\alpha^{\star}=\pi^{\star}(S_t, \mathbf{y}) = \mathop{\arg \min}_{\alpha \in {\cal A}} L(S_t(\alpha,\pi^{\star}),\mathbf{y})$$Only available for the training data: an expert
demonstrating how to perform the task

Expert policy¶
In pairs: What action should $\pi^{\star}$ return?
Takes previous actions into account (dynamic vs static)
Finding the optimal action can be expensive but we can learn with sub-optimal experts.
Imitation learning for part-of-speech tagging¶
Task loss: Hamming loss: number of incorrectly predicted tags
Transition system: Tag each token left-to-right
Expert policy: Return the next tag from the gold standard
Gold standard in search space
paths = [[],[(0,4),(1,3)],[(0,4),(1,3),(2,2)],[(0,4),(1,3),(2,2),(3,1)]]
rows = ['Noun', 'Verb', 'Modal', 'Pronoun','NULL']
columns = ['NULL','I', 'can', 'fly']
cbs = []
for path in paths:
cbs.append(cg.draw_cost_breakdown(rows, columns, path))
util.Carousel(cbs)
- Three actions to complete the output
- Expert policy replicates the gold standard
Training a classifier with structure features
gold_path = [(0,4),(1,3),(2,2),(3,1)]
cb_gold = cg.draw_cost_breakdown(rows, columns, gold_path)
cb_gold
Algorithm¶
\begin{align} & \textbf{Input:} \; D_{train} = \{(\mathbf{x}^1,\mathbf{y}^1)...(\mathbf{x}^M,\mathbf{y}^M)\}, \; \text{expert}\; \pi^{\star}, \; \text{classifier} \; H\\ & \text{set training examples}\; \cal E = \emptyset\\ & \mathbf{for} \; (\mathbf{x},\mathbf{y}) \in D_{train} \; \mathbf{do}\\ & \quad \text{generate expert trajectory} \; \alpha_1^{\star}\dots \alpha_T^{\star} = \pi^{\star}(\mathbf{x},\mathbf{y})\\ & \quad \mathbf{for} \; \alpha^{\star}_t \in \alpha_1^{\star}\dots \alpha_T^{\star} \; \mathbf{do}\\ & \quad \quad \text{extract features}\; \mathit{feat}=\phi(\mathbf{x},S_{t-1}) \\ & \quad \quad \cal E = \cal E \cup (\mathit{feat},\alpha^{\star}_t)\\ & \text{learn} \; H\; \text{from}\; \cal E\\ \end{align}
Exposure bias¶
wrong_path = [(0,4),(1,3),(2,1)]
cb_wrong = cg.draw_cost_breakdown(rows, columns, wrong_path)
util.Carousel([cb_gold, cb_wrong])
We had seen:
but not:

Define a rollin policy that sometimes uses the expert $\pi^{\star}$ and other times the classifier $H$:
$$\pi^{in} = \beta\pi^{\star} + (1-\beta)H$$DAgger algorithm¶
\begin{align} & \textbf{Input:} \; D_{train} = \{(\mathbf{x}^1,\mathbf{y}^1)...(\mathbf{x}^M,\mathbf{y}^M)\}, \; \text{expert}\; \pi^{\star}, \; \text{classifier} \; H\\ & \text{set training examples}\; \cal E = \emptyset ,\; \color{red}{\pi^{\star}\; \mathrm{probability}\; \beta=1}\\ & \mathbf{while}\; \text{termination condition not reached}\; \mathbf{do}\\ & \quad \color{red}{\text{set rollin policy} \; \pi^{in} = \beta\pi^{\star} + (1-\beta)H}\\ & \quad \mathbf{for} \; (\mathbf{x},\mathbf{y}) \in D_{train} \; \mathbf{do}\\ & \quad \quad \color{red}{\text{generate trajectory} \; \hat \alpha_1\dots\hat \alpha_T = \pi^{in}(\mathbf{x},\mathbf{y})}\\ & \quad \quad \mathbf{for} \; \hat \alpha_t \in \hat \alpha_1\dots\hat \alpha_T \; \mathbf{do}\\ & \quad \quad \quad \color{red}{\text{ask expert for best action}\; \alpha^{\star} = \pi^{\star}(\mathbf{x},S_{t-1})} \\ & \quad \quad \quad \text{extract features} \; \mathit{feat}=\phi(\mathbf{x},S_{t-1}) \\ & \quad \quad \quad \cal E = \cal E \cup (\mathit{feat},\alpha^{\star})\\ & \quad \text{learn}\; H \; \text{from}\; \cal E\\ & \quad \color{red}{\text{decrease} \; \beta}\\ \end{align}
DAgger algorithm¶
Proposed by Ross et al. (2011) motivated by robotics
- first iteration is standard classification training
- task loss and gold standard are implicitly considered via the expert
- DAgger: the Datasets in each iteration are Aggregated
rollins help recover from previous mistakes. How do we learn the future impact of a mistake?
rollout: try each action available and see what happens when future actions are taken by mixing the classifier and the expert
Rollins and rollouts¶
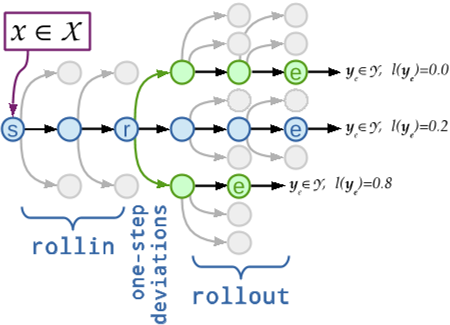
- first proposed in SEARN (Daumé III et al., 2009)
- used to hybridise DAgger by Vlachos and Clark (2014)
- Locally Optimal Learning to Search (Chang et al., 2015)
Let's see some applications¶
Remember this?
Learning a classifier¶
dep_rows = ['SHIFT', 'REDUCE', 'ARC-L', 'ARC-R','NULL']
dep_columns = ['S0','S1', 'S2', 'S3']
dep_cbs = []
dep_paths = [[],[(0,4),(1,0)],[(0,4),(1,0),(2,0)],[(0,4),(1,0),(2,0),(3,2)]]
for path in dep_paths:
dep_cbs.append(cg.draw_cost_breakdown(dep_rows, dep_columns, path))
util.Carousel(dep_cbs)
Features

Stack = [ROOT, had, effect]
Buffer = [on, financial, markets, .]
Features based on the words/PoS in stack and buffer:
wordS1=effect, wordB1=on, wordS2=had, posS1=NOUN, etc.
Features based on the dependencies so far:
depS1=dobj, depLeftChildS1=amod, depRightChildS1=NULL, etc.
Features based on previous transitions:
$r_{t-1}=\text{Right-Arc}(dobj)$, etc.
When we fall off the trajectory¶
- No suitable training data to teach us what to do.
- Next gold action might not be possible/optimal
Finding the best action¶
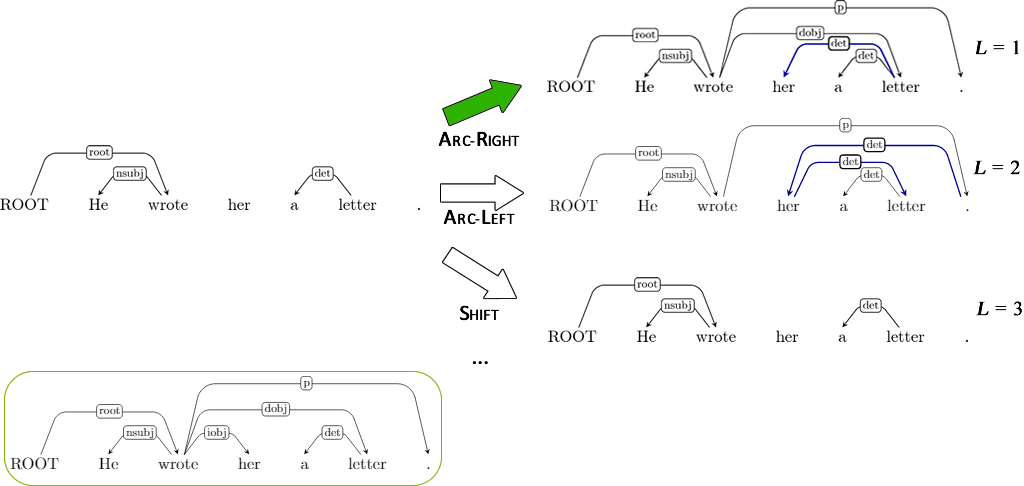
SHIFT would be the best if everything had been correct (Loss=0), but not anymore.
Imitation learning for dependency parsing¶
\begin{align} & \textbf{Input:} \; D_{train} = \{(\mathbf{x}^1,\mathbf{y}^1)...(\mathbf{x}^M,\mathbf{y}^M)\}, \; \text{expert}\; \pi^{\star}, \; \text{classifier} \; H\\ & \text{set training examples}\; \cal E = \emptyset ,\; \color{red}{\pi^{\star}\; \mathrm{probability}\; \beta=1}\\ & \mathbf{while}\; \text{termination condition not reached}\; \mathbf{do}\\ & \quad \color{red}{\text{set rollin policy} \; \pi^{in} = \beta\pi^{\star} + (1-\beta)H}\\ & \quad \mathbf{for} \; (\mathbf{x},\mathbf{y}) \in D_{train} \; \mathbf{do}\\ & \quad \quad \color{red}{\text{generate trajectory} \; \hat \alpha_1\dots\hat \alpha_T = \pi^{in}(\mathbf{x},\mathbf{y})}\\ & \quad \quad \mathbf{for} \; \hat \alpha_t \in \hat \alpha_1\dots\hat \alpha_T \; \mathbf{do}\\ & \quad \quad \quad \color{red}{\text{ask expert for best action}\; \alpha^{\star} = \pi^{\star}(\mathbf{x},S_{t-1})} \\ & \quad \quad \quad \text{extract features} \; \mathit{feat}=\phi(\mathbf{x},S_{t-1}) \\ & \quad \quad \quad \cal E = \cal E \cup (\mathit{feat},\alpha^{\star})\\ & \quad \text{learn}\; H \; \text{from}\; \cal E\\ & \quad \color{red}{\text{decrease} \; \beta}\\ \end{align}
Expert policy¶

Just like the oracle, but it takes the previous actions into account (dynamic oracle)
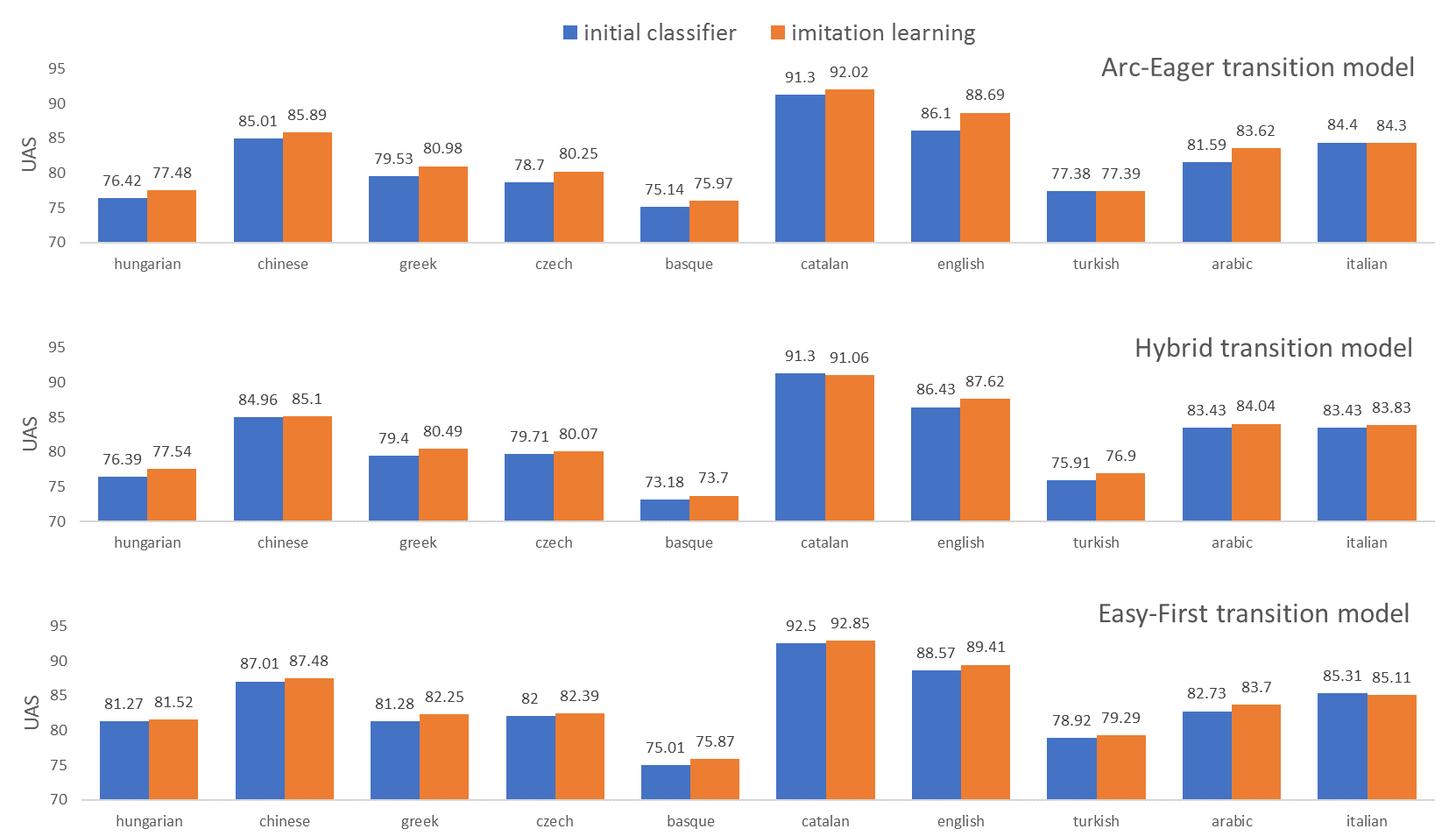
Results[Goldberg and Nivre 2012](http://www.aclweb.org/anthology/C12-1059)
¶
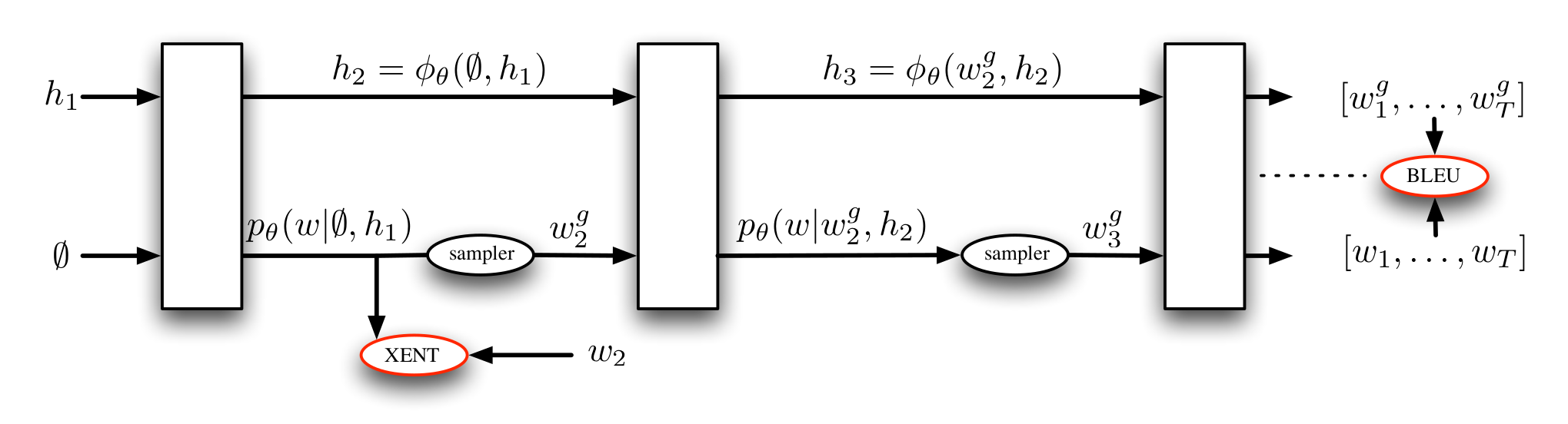
Recurrent Neural Network training
(Ranzato et al., 2016)
And some of my own:
Summary¶
Imitation learning:
- better training data for incremental predictors
- addresses error propagation
- many successful applications
Coming up next¶


...for your hard work during the module and your feedback!
Please give more feedback on the course in the forms provided by the department!
Future students will be grateful!