Imitation learning
Imitation learning for part-of-speech tagging¶
Task loss: Hamming loss: number of incorrectly predicted tags
Transition system: Tag each token left-to-right
Expert policy: Return the next tag from the gold standard
Gold standard in search space
paths = [[],[(0,4),(1,3)],[(0,4),(1,3),(2,2)],[(0,4),(1,3),(2,2),(3,1)]]
rows = ['Noun', 'Verb', 'Modal', 'Pronoun','NULL']
columns = ['NULL','I', 'can', 'fly']
cbs = []
for path in paths:
cbs.append(cg.draw_cost_breakdown(rows, columns, path))
util.Carousel(cbs)
- Three actions to complete the output
- Expert policy replicates the gold standard
Training a classifier with structure features
gold_path = [(0,4),(1,3),(2,2),(3,1)]
cb_gold = cg.draw_cost_breakdown(rows, columns, gold_path)
cb_gold
Algorithm¶
\begin{align} & \textbf{Input:} \; D_{train} = \{(\mathbf{x}^1,\mathbf{y}^1)...(\mathbf{x}^M,\mathbf{y}^M)\}, \; \text{expert}\; \pi^{\star}, \; \text{classifier} \; H\\ & \text{set training examples}\; \cal E = \emptyset\\ & \mathbf{for} \; (\mathbf{x},\mathbf{y}) \in D_{train} \; \mathbf{do}\\ & \quad \text{generate expert trajectory} \; \alpha_1^{\star}\dots \alpha_T^{\star} = \pi^{\star}(\mathbf{x},\mathbf{y})\\ & \quad \mathbf{for} \; \alpha^{\star}_t \in \alpha_1^{\star}\dots \alpha_T^{\star} \; \mathbf{do}\\ & \quad \quad \text{extract features}\; \mathit{feat}=\phi(\mathbf{x},S_{t-1}) \\ & \quad \quad \cal E = \cal E \cup (\mathit{feat},\alpha^{\star}_t)\\ & \text{learn} \; H\; \text{from}\; \cal E\\ \end{align}
With logistic regression and $k$ previous tags: training a $kth$-order Maximum Entropy Markov Model (McCallum et al., 2000)
Exposure bias¶
wrong_path = [(0,4),(1,3),(2,1)]
cb_wrong = cg.draw_cost_breakdown(rows, columns, wrong_path)
util.Carousel([cb_gold, cb_wrong])
We had seen:
but not:

Define a rollin policy that sometimes uses the expert $\pi^{\star}$ and other times the classifier $H$:
$$\pi^{in} = \beta\pi^{\star} + (1-\beta)H$$DAgger algorithm¶
\begin{align} & \textbf{Input:} \; D_{train} = \{(\mathbf{x}^1,\mathbf{y}^1)...(\mathbf{x}^M,\mathbf{y}^M)\}, \; \text{expert}\; \pi^{\star}, \; \text{classifier} \; H\\ & \text{set training examples}\; \cal E = \emptyset ,\; \color{red}{\pi^{\star}\; \mathrm{probability}\; \beta=1}\\ & \mathbf{while}\; \text{termination condition not reached}\; \mathbf{do}\\ & \quad \color{red}{\text{set rollin policy} \; \pi^{in} = \beta\pi^{\star} + (1-\beta)H}\\ & \quad \mathbf{for} \; (\mathbf{x},\mathbf{y}) \in D_{train} \; \mathbf{do}\\ & \quad \quad \color{red}{\text{generate trajectory} \; \hat \alpha_1\dots\hat \alpha_T = \pi^{in}(\mathbf{x},\mathbf{y})}\\ & \quad \quad \mathbf{for} \; \hat \alpha_t \in \hat \alpha_1\dots\hat \alpha_T \; \mathbf{do}\\ & \quad \quad \quad \color{red}{\text{ask expert for best action}\; \alpha^{\star} = \pi^{\star}(\mathbf{x},S_{t-1})} \\ & \quad \quad \quad \text{extract features} \; \mathit{feat}=\phi(\mathbf{x},S_{t-1}) \\ & \quad \quad \quad \cal E = \cal E \cup (\mathit{feat},\alpha^{\star})\\ & \quad \text{learn}\; H \; \text{from}\; \cal E\\ & \quad \color{red}{\text{decrease} \; \beta}\\ \end{align}
Proposed by Ross et al. (2011) motivated by robotics
- first iteration is standard classification training
- task loss and gold standard are implicitly considered via the expert
- DAgger: the Datasets in each iteration are Aggregated
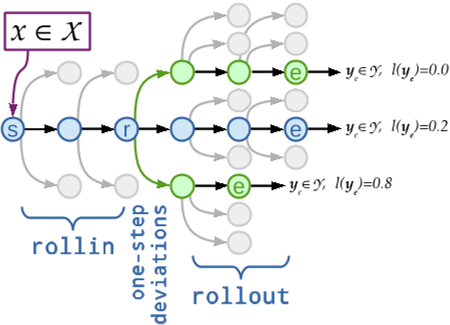
rollins expose to previous mistakes. Future ones?
rollouts: expose the classifier to future mistakes!
Training labels as costs¶
cb_gold
Cost break down
p = gold_path.copy()
cost = 1
cb_costs = []
cb_costs.append(cg.draw_cost_breakdown(rows, columns, [(0,4),(1,3)], roll_in_cell=p[1]))
cb_costs.append(cg.draw_cost_breakdown(rows, columns, [(0,4),(1,3),(2,0)], roll_in_cell=p[1], explore_cell=(2,0)))
cb_costs.append(cg.draw_cost_breakdown(rows, columns, [(0,4),(1,3),(2,0),(3,1)], roll_in_cell=p[1], explore_cell=(2,0),roll_out_cell=(3,0)))
cb_costs.append(cg.draw_cost_breakdown(rows, columns, [(0,4),(1,3),(2,0),(3,1)], cost, p[3], roll_in_cell=p[1], explore_cell=(2,0),roll_out_cell=(3,0)))
for i in range(1,4):
p = gold_path.copy()
p[2] = (gold_path[2][0],i)
if p == gold_path:
cost = 0
else:
cost = 1
cb_costs.append(cg.draw_cost_breakdown(rows, columns, p, cost, p[3], roll_in_cell=p[1],roll_out_cell=(3,0), explore_cell=p[2]))
util.Carousel(cb_costs)