
How to use expert help
for structured prediction
How to use expert help
for structured prediction
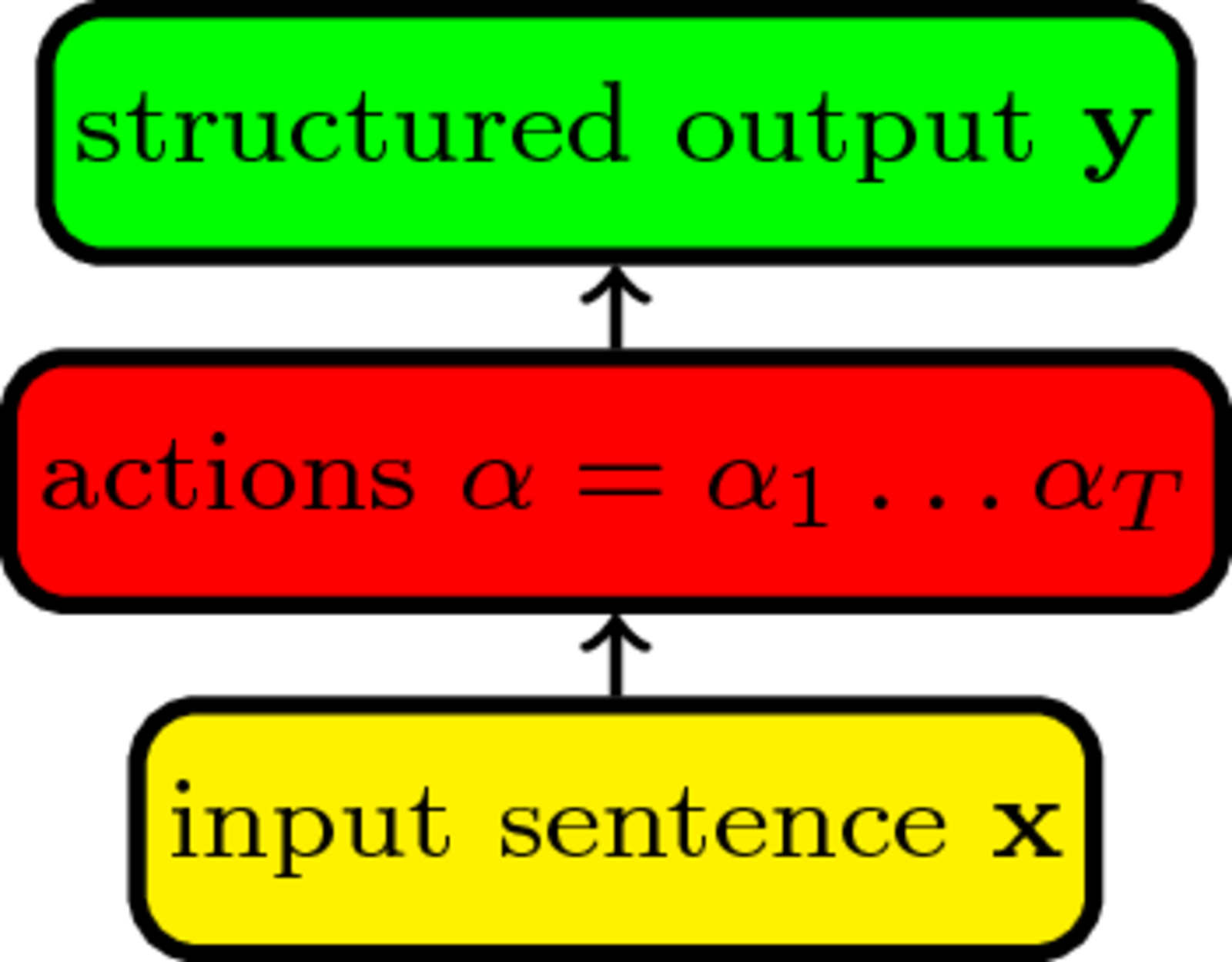
Imitation learning is a learning paradigm originally developed to learn robotic controllers from demonstrations by humans, e.g. autonomous flight from pilot demonstrations. Recently, algorithms for structured prediction were proposed under this paradigm and have been applied successfully to a number of tasks including syntactic dependency parsing, information extraction, coreference resolution, dynamic feature selection, semantic parsing and natural language generation. Key advantages are the ability to handle large output search spaces and to learn with non-decomposable loss functions. Our aim in this tutorial is to have a unified presentation of the various imitation algorithms for structure prediction, and show how they can be applied to a variety of NLP applications.
In the first part, we will give a unified presentation of imitation learning for structured prediction focusing on the intuition behind the framework. We will then delve into the details of the different algorithms that have been proposed so far under the imitation learning paradigm. Furthermore, we will give a comparative overview of the various algorithms presented that will expose their differences and their practical implications. We will conclude by discussing the relation of imitation learning to recurrent neural networks, bandit learning, adversarial learning, and reinforcement learning.
Part II: Applications in NLPIn the second part, we will discuss recent work applying imitation learning methods in the context of NLP. We will begin by reviewing the application of imitation learning on syntactic dependency parsers and discuss how to create dynamic oracles. Furthermore, we will review how imitation learning is applied on semantic parsing, and how it can benefit natural language generation, where the search space is all English sentences. In this process we will explain techniques that work to augment imitation learning and solve problems that arise in each particular application, such as focused costing, noise reduction, targeted exploration, sequence correction, and change propagation. Finally, we will briefly present applications on biomedical event extraction, feature selection, coreference resolution, autonomous driving learning, and pruning policies for syntactic parsing.
Part I: Imitation Learning Algorithms (90 minutes)
Break! (15 minutes)
Part II: Applications (90 minutes) (NOTE: These are the html/reveal.js versions of the slides which should be fine for the browser (tested in Chrome). If you want PDFs, just add?print-pdf to the link and print.
For jupyter+python dynamic versions (with some more animations) you need to clone the
github repo.)